.png)
.png)
What we learned building renter-first content that earns citations from ChatGPT, Perplexity, and Google AI Overviews.
Three months ago, brightplace did not exist as far as any AI assistant was concerned. Today, our content surfaces in AI-generated answers across hundreds of distinct renter searches. More than 30 of those are full citations with direct brand mentions, where ChatGPT, Perplexity, Google AI Overviews, or Claude names or links brightplace as a source.
We got there with no backlink campaigns, no paid distribution, and a four-person team. What made it possible was treating AI citation as its own discipline, with rules that diverge from the SEO playbook everyone already knows. The page that earns a citation is not always the page that would have ranked first on Google. A model deciding what to quote weighs different things than a person skimming a results list, and the gap between those two is where the opportunity lives.
Here is what we built, what actually earned the citations, the infrastructure bugs that nearly cost us all of them, and what we would tell another team starting from zero.
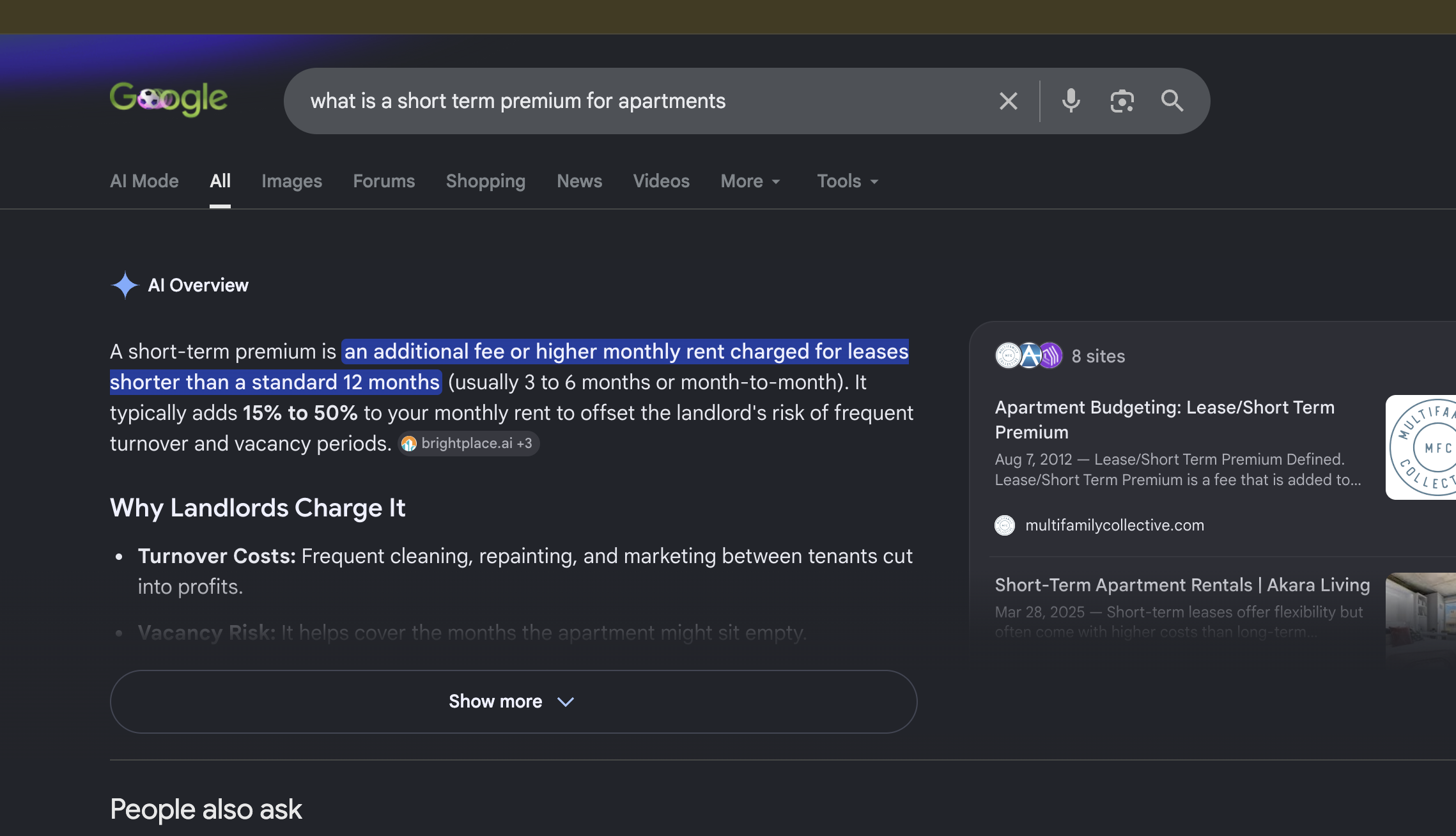
A Google AI Overview answering a renter's question about short-term lease premiums, citing brightplace.ai.
For the most part, AI assistants do not invent answers about real estate; they assemble them from the indexed content they can find and trust. For most rental queries, that pool is thin: listing aggregators, stale forum threads, and blog posts optimized for a search era that is ending. The information is generic, rarely current, and almost never structured around the question the renter actually asked.
That is the gap. If no one is producing renter-first, factually accurate, well-structured content for these queries, the first source that does earns the citation by default. So we set out to be that source, deliberately and at scale.
The first source to publish accurate, structured, renter-first content earns the citation by default. We decided to be that source.
brightplace is an AI-native company, and our content operation is built the way we build everything, as a partnership between machine scale and human judgment. AI handles the work it is genuinely better at: agentic SERP scraping, harvesting the questions renters are actually asking, competitive data extraction, schema generation, and automated quality checks. Humans handle the work that requires judgment: deciding what to publish, writing it, and owning the voice, the framing, and the accuracy. The content is written by our team. The engine around it is what lets four people move like a much larger one.
AI-driven research and briefing. Before a word is written, our system assembles the raw material: agentic SERP scraping, People Also Ask harvesting, competitive coverage analysis, and live market data extraction. That feeds a structured brief defining the section structure, the FAQ targets, the proof points, and the citability requirements. The machine does the gathering at a speed and breadth no person could match; the team decides the angle and what the piece needs to prove.
Human-led writing. Our team writes each piece against that brief. Every claim is sourced, every figure is date-stamped, every section is structured to answer the question first. This is the part we do not delegate: the editorial judgment, the voice, the framing, and the accuracy are ours. The research engine clears the runway; the writing is human.
AI-assisted quality assurance. Each draft runs through an automated QA pass of 22 checks. Some are structural, like validating heading hierarchy and checking every internal link against the live sitemap. Some are compliance, like screening for Fair Housing language and verifying each figure against its cited source. The machine catches what tired human eyes miss at volume. Nothing ships with a broken link, an unsupported number, or a structural flaw, and a human makes the final call on anything the checks flag.
Automated publishing. Approved content is converted to HTML, pushed to our Webflow CMS, and published with JSON-LD schema generated for every page: Article, BreadcrumbList, and FAQPage types. The structured data is consistent because the process is, not because someone remembered to add it.
The result: a repeatable path from keyword to a published, citation-ready article: AI doing the machine-scale work, humans owning the editorial standard that makes the content worth citing in the first place.
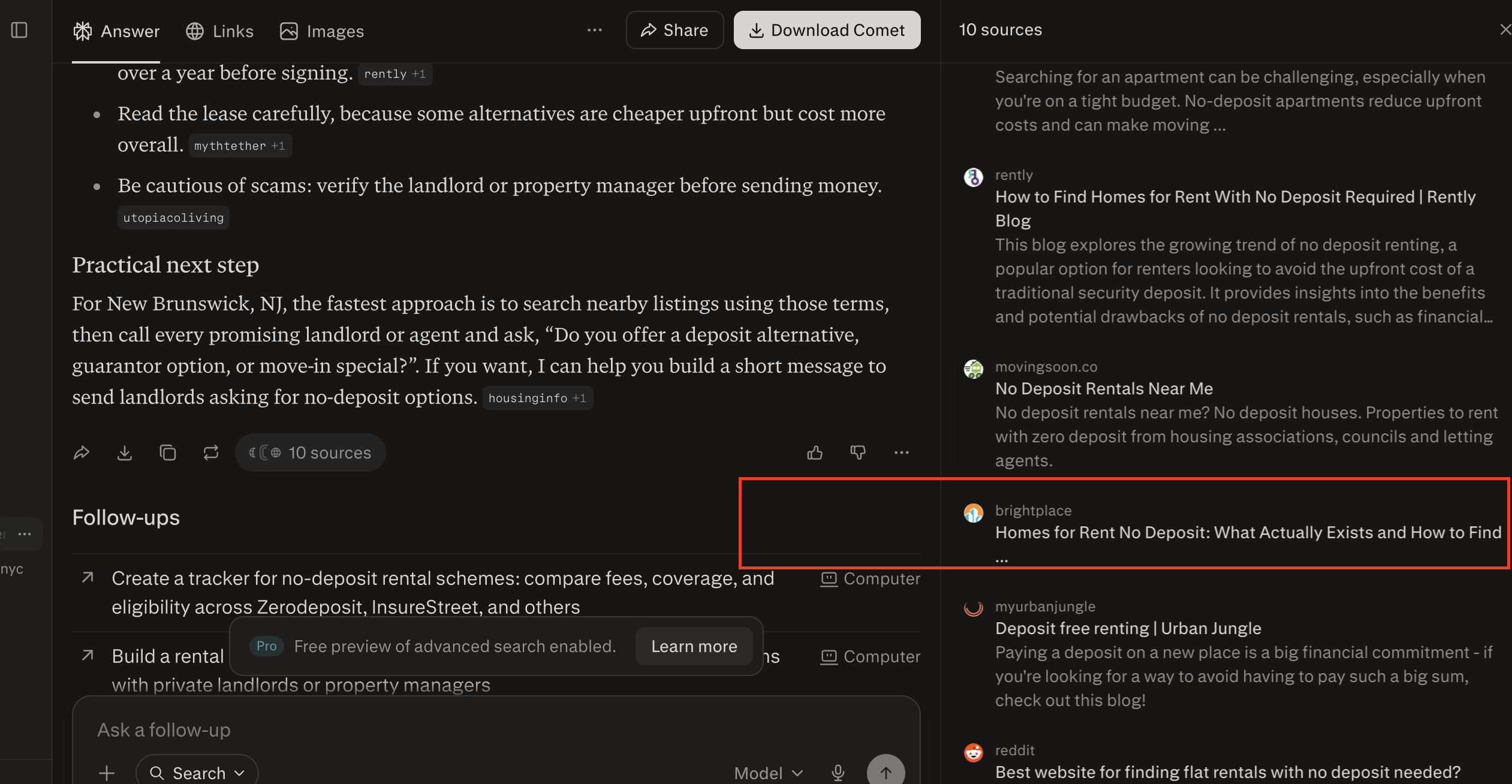
A Perplexity answer on no-deposit rentals citing brightplace among its ten sources.
Not all content earns citations, and it should not. AI engines are selective about what they pull into an answer. What follows is what we observed moving the needle for us, offered as patterns from our own data rather than universal laws.
Answer-first structure. Every section opens with a direct answer in the first sentence. In our experience, AI engines tend to pull from the opening of a section, so an answer buried three paragraphs down is more likely to be passed over. Leading with the answer has been the highest-impact structural choice we have made.
Date-stamped specificity. Every figure is attributed to a market and a moment in time, such as "(as of Q2 2026)." Models appear to favor sources that look current and verifiable over sources that assert facts with no context. Specificity reads as trustworthiness.
FAQ sections with standalone answers. Each FAQ answer is a self-contained 40–60 word paragraph that responds directly to the question. In our data these have been among the highest-probability extraction targets for AI Overviews and Perplexity. Google fully retired FAQ rich results on May 7, 2026, after restricting them to government and health sites back in 2023, but the structure still helps AI citation because it makes answers trivial to parse.
Outbound authority links. Every article links to 3–5 authoritative sources: HUD, CFPB, FTC, state housing authorities, official transit agencies. Google's March and May 2026 core updates rewarded original, first-party sources and pushed aggregators and thin content down. Our read is that AI engines lean the same way: a page that points to primary sources is easier to trust and verify, so sources that cite trustworthy references get favored. When we published articles without these links, they underperformed. Adding them tracked with recovery.
Source discipline. We do not cite listing aggregators or review platforms. The models already have those sources. Pointing to them adds nothing. Citing the .gov references that models trust but competitors ignore is precisely what sets our content apart.
Here is the picture at 90 days. brightplace content surfaces in AI-generated answers across hundreds of distinct renter searches. More than 30 of those are full citations, where the assistant names or links brightplace as a source, and five name the brand directly. On the traditional side, June 2026 was our first full month of meaningful traffic: several hundred unique visitors to brightplace.ai, building toward our first thousand, spread across dozens of articles rather than concentrated in one.
A word on how we count. We treat a citation as an AI answer that names or links brightplace as a source. That is a stricter bar than an appearance, where our content shapes the answer without formal attribution. The hundreds of appearances are the top of the funnel; the 30+ citations are the share that turn into visible credit.
The four surfaces do not behave the same way. ChatGPT, Perplexity, Google AI Overviews, and Claude each weight and display sources differently, so the same article can earn a named citation on one and an uncredited mention on another. We optimize for the pattern common to all of them rather than for any single surface.
The growth curve is not dramatic; it is steady, and that is the point. Each article earns its own slice of traffic and its own citations. The compounding shows up when dozens of articles each pull steady monthly visits and each earn a citation or two. That is how a three-month-old site with no domain authority starts appearing exactly where renters are now searching.
The articles were strong from the start. The infrastructure around them had bugs, and infrastructure bugs compound faster than content quality. These are the kinds of failures that quietly kill a content program, so we are sharing them plainly.
Schema URLs pointing to 404s. Our article schemas referenced /knowledgebase/ paths while the live pages sat at /resources/. Google saw structured data pointing to URLs that did not exist. Every article carried the bug, and it took weeks to catch. Correcting it across 27 articles and republishing cost a full day.
Missing outbound links. Our first batch of 18 articles shipped without links to authoritative sources. After Google's May 2026 core update, several lost ranking. Adding 3–5 .gov links per article and republishing tracked with most positions recovering within two weeks.
Broken internal links. Five early articles used legacy CMS slugs that no longer matched their published URLs, sending readers into 404s. We caught it only during a ranking-drop investigation. We now validate every internal link against the live sitemap before publishing.
Fonts throttling page speed. Five unsubset font files totaling 12.8 MB were loading on every page, dragging mobile performance to a score of 67. They were full Unicode character sets when we only needed Latin. The remedy is straightforward: subset the fonts to the Latin set they actually need, and that change is queued as our next performance fix.
Build the operation before you scale the content. A single excellent article is worth less than a disciplined operation that ships many good articles with correct structure, links, and schema every time. The operation compounds; the one-off does not.
Treat the brief as a contract. Accuracy, voice, structure, and proof points are decided in the brief, not improvised in the draft. Discipline at the briefing stage is where compliance and consistency come from.
Validate against the live site, not your local files. Schema URLs, internal links, and CMS slugs drift between what is in your drafts and what is actually live. Checking every link against the sitemap before publishing would have prevented three of our four infrastructure bugs.
Outbound authority links are not optional. Google's 2026 updates made them a real ranking factor, and AI engines weight sources that reference .gov and .edu material. Every article needs 3–5. Publish without them and you will be back to add them later.
FAQ structure is your highest-value asset. Even with FAQ rich results retired, AI engines still parse FAQ structured data for answer extraction. A standalone 40–60 word answer to a real question is what gets pulled into AI Overviews, Perplexity, and ChatGPT citations.
The operation runs continuously. New briefs are generated as search patterns shift, existing articles are audited whenever Google ships an update, and stale data gets refreshed before it can cost us a citation.
There is a second half to the strategy. brightplace Connect, our MCP server, lets AI assistants move from citing our content to acting on our data: searching listings, pulling property details, and booking tours on a renter's behalf. If you are building an AI assistant that helps renters, Connect is live at mcp.brightplace.ai/mcp; point your client at the endpoint and it can work against real brightplace data. The content earns the citation; Connect earns the action. Both follow the same principle: be the source that deserves to be there.
Three months in, the citations are compounding, the operation scales without adding headcount, and renters asking AI assistants for help are getting better answers because of it.
brightplace is live at app.brightplace.ai. The knowledgebase is at brightplace.ai/resources. brightplace Connect is available at mcp.brightplace.ai/mcp. Docs at docs.brightplace.ai.
About brightplace. brightplace is an AI-native apartment rental discovery platform helping renters find and act on the right home through accurate, renter-first content and an MCP server that lets AI assistants work directly with brightplace data.
We'll find a place that you'll actually love